This guide provides comprehensive instructions for deploying and managing the High Availability NVMe Storage Cluster system - a reference architecture high-performance storage solution integrating a high-density dual-node server platform, SupremeRAID™ HE, and BeeGFS parallel file system. This enterprise-grade storage infrastructure delivers exceptional performance, scalability, and reliability for data-intensive computing environments. This document guides system administrators and storage engineers through the complete deployment lifecycle, from initial system preparation to ongoing maintenance and troubleshooting. By following these procedures, technical staff can efficiently implement, verify, and maintain their High Availability NVMe Storage Cluster infrastructure to ensure optimal performance and availability.
In today’s data-driven landscape, enterprises and high-performance computing (HPC) environments demand storage solutions that deliver exceptional speed, scalability, and resilience while optimizing cost-efficiency. Graid Technology introduces SupremeRAID™ HE, a cutting-edge GPU-accelerated NVMe RAID solution with array migration and cross-node high-availability (HA) capabilities, paired with a 2U all-flash Storage Bridge Bay (SBB) system and the BeeGFS parallel file system. Highlighting its performance, this architecture achieves the world’s highest throughput in a 2U system, saturating a 400Gb/s network with up to 132 GB/s read and 83 GB/s write locally, and up to 93 GB/s read and 84 GB/s write from the client side, while eliminating cross-node replication for cost savings and scaling seamlessly. Unlike advanced software RAID approaches, SupremeRAID™ HE leverages GPU parallelism to maximize NVMe performance, eliminate CPU bottlenecks, and reduce total cost of ownership (TCO). This whitepaper explores how this innovative design meets evolving demands.
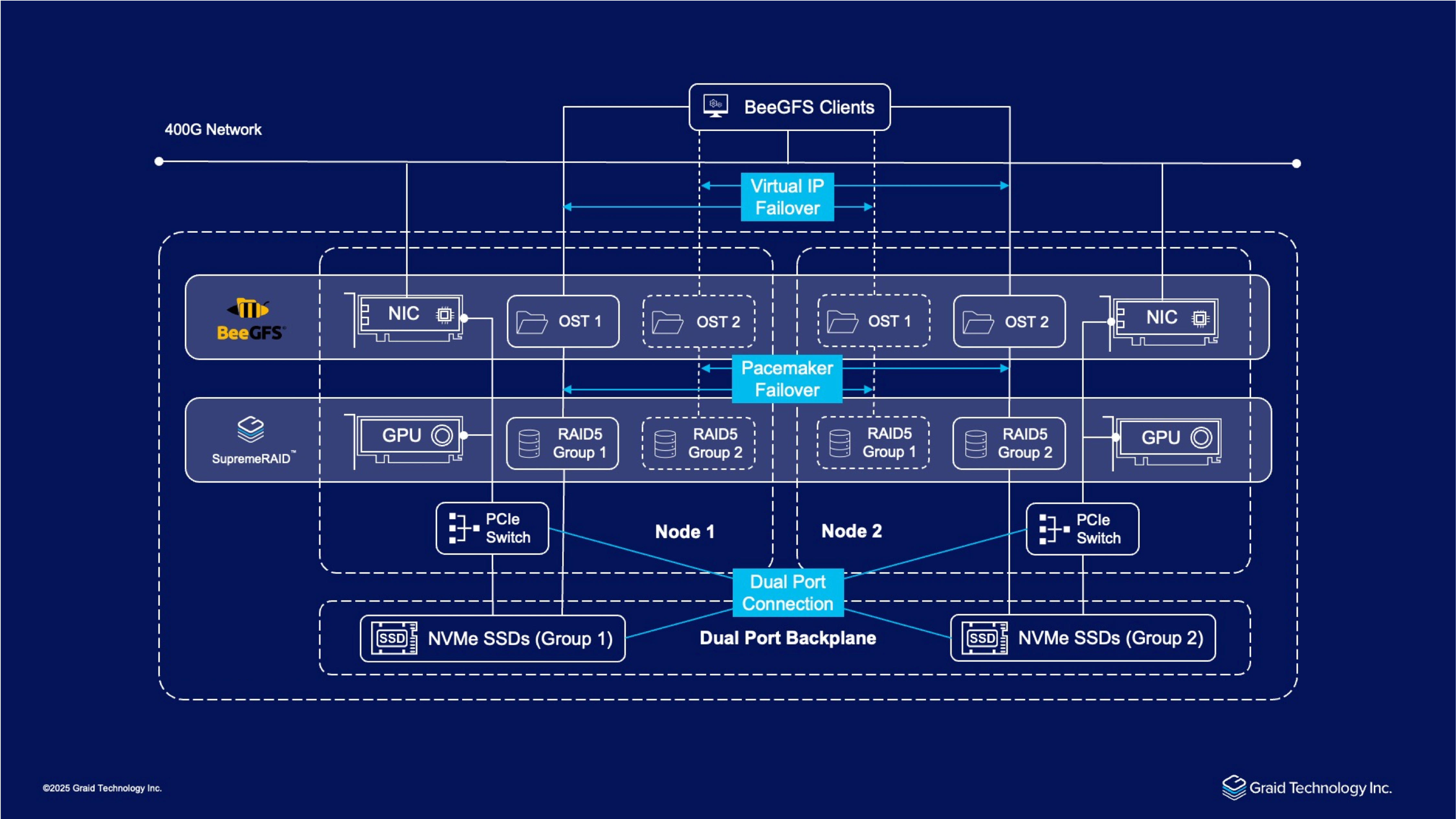
SupremeRAID™ HE integrates with a dual-node SBB server and BeeGFS to form a high-performance, highly available NVMe storage platform. Unlike software RAID, which consumes significant CPU resources, SupremeRAID™ HE offloads RAID operations to a GPU, preserving CPU capacity for critical upper-layer applications like BeeGFS. This GPU-accelerated approach, combined with array migration for cross-node high availability (HA), delivers exceptional throughput while supporting up to 32 drives in a compact 2U footprint. By reducing CPU overhead, it streamlines system performance, enhances scalability, and lowers total cost of ownership (TCO) for data-intensive enterprise and HPC workloads, offering a cost-effective and efficient alternative to advanced software RAID solutions.
SupremeRAID™ HE, developed by Graid Technology, is a GPU-accelerated NVMe RAID solution featuring array migration for cross-node high availability (HA). It supports configurations with up to 32 drives and delivers exceptional throughput. By leveraging GPU computing power and patented out-of-path data protection technology, it maximizes NVMe performance, ensures zero-downtime HA, and reduces total cost of ownership (TCO) by eliminating data replication.
BeeGFS, an open-source POSIX file system from the Fraunhofer Institute, is built for HPC with parallel data access, scalability, and fault tolerance via distributed metadata and data. It delivers high-throughput I/O with low overhead, making it ideal for data-intensive workloads in scalable NVMe environments.
This solution leverages a server's dual-node architecture, enhanced by SupremeRAID™ HE’s array migration capabilities, to deliver exceptional performance and robust high availability (HA) within a 2U chassis. Integrated into a 400G network, the system connects seamlessly with BeeGFS clients, optimizing resource utilization by eliminating cross-node data replication and reducing costs. The design supports linear scalability, allowing additional SBB units to expand capacity and performance as needed.
The solution features two SBB nodes, each equipped with a PCIe switch for internal data routing and connected via a dual-port backplane that enables both nodes to access 24 NVMe SSDs, organized into two groups of 12. Each node includes a Network Interface Card (NIC) and a GPU, with SupremeRAID™ HE utilizing GPU acceleration to offload RAID operations, enhancing throughput and preserving CPU resources. The setup is tested over a 400G network infrastructure.
SupremeRAID™ HE manages the 24 dual-port NVMe SSDs, with each node handling 12 drives. This configuration supports the system’s high-performance capabilities.
Metadata Target (MDT):
Configured as RAID 10 with 2 drives per node (4 total), forming 4 virtual drives for low-latency metadata operations.
Object Storage Target (OST):
Configured as RAID 5 or RAID 6 with 10 drives per node (20 total across both nodes), creating multiple virtual drives for high-capacity, fault-tolerant data storage.
High availability is ensured through Pacemaker, which manages failover using a virtual IP, maintaining service continuity during node failures. SupremeRAID™ HE’s array migration enables seamless RAID array transfers between nodes, eliminating replication needs and optimizing NVMe usage. The dual-port backplane and 400G network connectivity enhance fault tolerance and data throughput.
Please note that this deployment guide utilizes proprietary tools from Graid Technology which are required for the setup. These tools are not included in the standard SupremeRAID™ HE driver packages.
High Availability NVMe Storage Cluster Setup Manager (bgfs-setup-manager): This package contains the beegfs_control.py script and related configuration files, used for deploying and managing the BeeGFS cluster.
SupremeRAID™ RAID Arrays Creation Script (create_bgfs_raid.py): This script is used to configure the SupremeRAID™ arrays for optimal performance with BeeGFS.
To obtain create_bgfs_raid.py and bgfs-setup-manager, please contact your Graid Technology technical support representative or sales window.
To avoid configuration conflicts, it is highly recommended to plan your IP allocation before deployment. The following table outlines the IP schema used in this document's examples:
Role
Hostname
System/Mgmt Network
BMC/IPMI Network
Storage Network (Data)
Heartbeat Network
Notes
Node A
bgfs-oss1
192.168.10.101
192.168.1.101
10.16.10.101 (Multi-NIC: 10.16.11.101)
192.168.20.101
Physical IP
Node B
bgfs-oss2
192.168.10.102
192.168.1.102
10.16.10.102 (Multi-NIC: 10.16.11.102)
192.168.20.102
Physical IP
Client
bgfs-client
192.168.10.201
N/A
10.16.10.201 (Multi-NIC: 10.16.11.201)
N/A
Client Node
Cluster VIP
(MGT-VIP)
192.168.10.100
N/A
N/A
N/A
Beegfs Mgmt Service VIP
Node A VIPs
(A-VIPs)
N/A
N/A
VIP1: 10.16.10.103 VIP2: 10.16.11.103
N/A
Node A Service VIPs
Node B VIPs
(B-VIPs)
N/A
N/A
VIP1: 10.16.10.104 VIP2: 10.16.11.104
N/A
Node B Service VIPs
Note
VIP (Virtual IP): Must be on the same subnet as the physical IP but must not be the same as any physical IP. For multi-NIC mode, each storage subnet requires a dedicated VIP, which must be added as a resource in the Pacemaker resource group.
System/Mgmt Network: Used for SSH, Pacemaker communication, and the BeeGFS management service.
BMC/IPMI Network: Used for STONITH Fencing.
Storage Network: Used for BeeGFS data traffic. High-speed networks like InfiniBand or RoCE are recommended.
Multi-NIC Recommendation: If the system has multiple high-speed network cards (e.g., ib0, ib1), we recommend assigning IPs from different subnets to each card (e.g., ib0: 10.16.10.x, ib1: 10.16.11.x) to enable BeeGFS multi-rail capabilities for maximum throughput.
Heartbeat Network: Used for Pacemaker node-to-node health checks. If your server model includes a dedicated Node-to-Node 1GbE internal port (not for external access), it is strongly recommended to use this port for the heartbeat network to protect it from external switch failures.
Configure hostnames for all nodes and ensure that hostnames and IP addresses can be resolved correctly across the cluster. This can be achieved by configuring a DNS service or by updating the /etc/hosts file on each server to ensure all nodes can communicate with each other by hostname.
Note
In this documentation, "bgfs-oss1" refers to Node A of the SBB (Storage Bridge Bay) system "bgfs-oss2" refers to Node B of the SBB system These hostnames represent the individual computing nodes within the dual-node enclosure
Ensure SSH access is properly configured between all nodes (optional):
For password-based authentication: ensure sshpass is installed
For key-based authentication (recommended): set up SSH keys as shown below
# [Please log in to Node A (bgfs-oss1) and execute the following command]# Generate SSH key if you don't already have onessh-keygen -t rsa -b4096# Copy the key to each nodefornodein bgfs-oss1 bgfs-oss2 bgfs-client;do ssh-copy-id root@$nodedone# Test SSH connectivity to each nodefornodein bgfs-oss1 bgfs-oss2 bgfs-client;dossh root@$nodeecho"SSH connection successful"done
In this documentation, "graid-sr-pre-installer-1.7.2-185-x86_64.run" is the latest version as of 2025/12/15. Please visit https://docs.graidtech.com/ to get the latest version.
Run the SupremeRAID™ pre-installer script to set up the environment:
# SR-HE-PRO-AM (SR-1000-AM/GPU: NVIDIA RTX A1000)# For RHEL/Rocky Linuxwget https://download.graidtech.com/driver/sr-he/linux/1.7.2/release/\graid-sr-he-1.7.2-57.gfbd894ea.pam.el9.6.x86_64.rpm# For Ubuntuwget https://download.graidtech.com/driver/sr-he/linux/1.7.2/release/\graid-sr-he-1.7.2-57.gfbd894ea.pam.x86_64.deb# SR-HE-ULTRA-AD (SR-1010-AD/GPU: NVIDIA RTX 2000 Ada)# For RHEL/Rocky Linuxwget https://download.graidtech.com/driver/sr-he/linux/1.7.2/release/\graid-sr-he-1.7.2-57.gfbd894ea.uad.el9.6.x86_64.rpm# For Ubuntuwget https://download.graidtech.com/driver/sr-he/linux/1.7.2/release/\graid-sr-he-1.7.2-57.gfbd894ea.uad.x86_64.deb
Install the SupremeRAID™ HE driver package:
For RHEL/Rocky Linux: sudo rpm -i graid-<version>.rpm
For Ubuntu: sudo dpkg -i graid-<version>.deb
Note
In this documentation, the "SupremeRAID™ HE driver package" is the latest version as of 2025/12/15. Please visit https://docs.graidtech.com/ to get the latest version.
If you want to use a SupremeRAID™ HE version other than SR-HE-PRO-AM or SR-HE-ULTRA-AD, please contact your Graid Technologies representative to obtain the correct driver package.
Apply the license key to activate the driver:
sudo graidctl apply license <your-license-key>
Note
The license key must correspond to your SupremeRAID™ HE driver. If you have a license for SupremeRAID™ SR or another driver, please contact your Graid Technologies representative.
Verify the driver installation:
sudo systemctl status graid
Important
For a dual-node system, repeat the SupremeRAID™ driver installation on both Node A (bgfs-oss1) and Node B (bgfs-oss2) with identical configuration to ensure proper dual-port SSD functionality.
cd /opt/beegfs_setup_managersudo pip install-r requirements.txt
Note
For Ubuntu 22 or 24 versions, if pip doesn't work correctly, consider using a virtual environment or following the warning messages to add any necessary flags. For example:
Use the create_bgfs_raid.py script to create optimized RAID arrays for BeeGFS. This script must be executed individually on each node.
# View help informationsudo python3 create_bgfs_raid.py --help# Without Hotspare# Example: Create 24 SSDs with Node A configuration# Node A:# [Please log in to Node A (bgfs-oss1) and execute the following command]sudo python3 create_bgfs_raid.py create 24 node_a# Example: Create 24 SSDs with Node B configuration# Node B:# [Please log in to Node B (bgfs-oss2) and execute the following command]sudo python3 create_bgfs_raid.py create 24 node_b# With Hotspare# Example: Create 24 SSDs with Node A configuration with Hotspare# Node A:# [Please log in to Node A (bgfs-oss1) and execute the following command]sudo python3 create_bgfs_raid.py create 24 node_a --hotspare# Example: Create 24 SSDs with Node B configuration# Node B:# [Please log in to Node B (bgfs-oss2) and execute the following command]sudo python3 create_bgfs_raid.py create 24 node_b --hotspare
The script performs these key operations:
Detects NVMe devices in the system
Groups devices by size and PCIe arrangement
Configures virtual drives (VDs) with optimal sizing
Note
This script must be run on both Node A (bgfs-oss1) and Node B (bgfs-oss2), using the appropriate command for each node.
To configure hot spares, you must apply the settings to both nodes to guarantee the integrity of the High Availability mechanism. Configuring a hot spare on only one node may cause the function to malfunction.
After creating the RAID arrays, verify the configuration:
# List drive groupssudo graidctl ls dg# List virtual drivessudo graidctl ls vd# Query the drive group UUIDs, which are needed for the BeeGFS cluster configuration later. # This command must be executed on each node (Node A and Node B). # Node A or Node Bsudo python3 create_bgfs_raid.py query-dg
Make note of the drive group UUIDs as they will be needed for the BeeGFS configuration.
Expect Output:
sudo graidctl ls dg✔List drive group successfully.│───────│───────│────────│──────────│─────────│─────────│───────────────────────│─────────││ DG ID │ MODE │ VD NUM │ CAPACITY │ FREE │ USED │ CONTROLLER │ STATE ││───────│───────│────────│──────────│─────────│─────────│───────────────────────│─────────││ 0 │ RAID5 │ 2 │ 23 TiB │ 240 MiB │ 23 TiB │ running: 0 prefer: 0 │ OPTIMAL ││ 9 │ RAID1 │ 9 │ 2.9 TiB │ 0 B │ 2.9 TiB │ │ OPTIMAL ││───────│───────│────────│──────────│─────────│─────────│───────────────────────│─────────│
To completely remove all RAID configuration from your system, you can use the purge command:
Warning
This action will permanently delete all data stored on the RAID array. Please ensure you have backed up any important data before proceeding.
To execute the RAID purge:
# Purge all the configuration # Node A or Node B# [Please login to Node A (bgfs-oss1) and Node B (bgfs-oss2) execute the following command]sudo python3 create_bgfs_raid.py purge
Update the following sections in the configuration file:
Basic Configuration Section This section contains fundamental settings that affect the overall operation:
# Basic Configurationconfig_ver:1ssh_password:"your_ssh_password"# Replace with your actual SSH password# NOTE: If using password auth, ensure all nodes (Node A, Node B, Client) have the same root password.log_file:"/var/log/beegfs_manager.log"root_mount_point:"/mnt/beegfs"
config_ver: DO NOT CHANGE THIS VALUE
ssh_password: Set this to the SSH password that will be used for remote connections if key-based authentication fails (optional).
log_file: The path where logs will be written. Ensure this path is accessible and writable.
root_mount_point: The base directory where BeeGFS will mount its storage and metadata services. BeeGFS Configuration Section This section defines the BeeGFS services configuration:
# BeeGFS Configurationbeegfs:mgmtd:# Management service config (required)base_port:8008host:"bgfs-oss1"# Primary management service hostsupremeraid:virtual_drive:"md55p5"# Actual virtual drive name from your configmeta:# Metadata config (required)base_port:8005naming_rule:"meta"hosts:-"bgfs-oss1"# Node A-"bgfs-oss2"# Node Bsupremeraid:-host:"beegfs-oss1"virtual_drive_pattern:"md55p"# Virtual drive pattern for metadata-host:"beegfs-oss2"virtual_drive_pattern:"md88p"# Virtual drive pattern for metadatastorage:# Storage config (required)base_port:8003naming_rule:"storage"hosts:-"bgfs-oss1"# Node A-"bgfs-oss2"# Node Bsupremeraid:virtual_drive_pattern:"gdg0n"# Virtual drive pattern for storageclient:# Client configuration (Optional)client_thirdparty_include_path:"/usr/src/ofa_kernel/default/include/"base_port:8004helper_base_port:8006hosts:-"bgfs-client"# Client node hostname
mgmtd: Configuration for the management service
host: Specify the hostname for the management service (typically Node A)
virtual_drive: The exact virtual drive name used for the management service, default name md0p5
meta and storage: Configuration for metadata and storage services
hosts: List of hostnames where these services will run
virtual_drive_pattern: The naming pattern for virtual drives (from graidctl ls vd)
client: Configuration for client services
client_thirdparty_include_path: Path to external libraries (especially important for InfiniBand) Pacemaker Configuration Section This section configures high availability using Pacemaker:
# Pacemaker Configurationpacemaker:stonith:enable:truedevices:-node: bgfs-oss1 # Node Aname: bgfs-oss1-fenceip: 192.168.1.101 # Replace with BMC IP address for Node Ausername: ADMIN # Replace with BMC usernamepassword: PASSWORD # Replace with BMC passwordhost_list: bgfs-oss1-node: bgfs-oss2 # Node Bname: bgfs-oss2-fenceip: 192.168.1.102 # Replace with BMC IP address for Node Busername: ADMIN # Replace with BMC usernamepassword: PASSWORD # Replace with BMC passwordhost_list: bgfs-oss2cluster_name: graid-clustercluster_username: haclustercluster_password: p@ssW0rd # Change this for production deploymentscluster_nodes:-node:"bgfs-oss1"# Node Aaddrs:- 192.168.10.101 # Replace with Node A IP address- 192.168.20.101 # Replace with Node A heartbeat IP address-node:"bgfs-oss2"# Node Baddrs:- 192.168.10.102 # Replace with Node B IP address- 192.168.20.102 # Replace with Node B heartbeat IP addressha_pair:-["bgfs-oss1","bgfs-oss2"]# Define the HA pair
enable: Set to true to enable Pacemaker for high availability
stonith: Configure fencing devices for each node
Replace IP addresses, usernames, and passwords with your actual BMC (Baseboard Management Controller) details
cluster_nodes: List of nodes with their IP addresses
Each node should have at least two addresses: primary and heartbeat
ha_pair: Define which nodes form high-availability pairs Resource Groups Configuration Section This section configures how resources are grouped and managed:
groups:-name: mgt-group# prefer_node: node for managementprefer_node:"bgfs-oss1"vip:resource_name: mgt-vip# Virtual IP for management (replace with your actual VIP)inet:"192.168.10.100/24"# Network interface (replace with your actual interface)nic_iflabel:"enp0s1:mgt"dg:resource_name: mgt-dguuids:-id:9# Replace with actual UUID (dg9) from `create_bgfs_raid.py query-dg`md_uuid: <mgt-dg-uuid>-name: a-group# prefer_node: node for Node Aprefer_node:"bgfs-oss1"vip:# Virtual IP-1 for Node A (replace with your actual VIP)-inet:"10.16.10.103/24"# Network interface (replace with your actual interface)nic_iflabel:"enp0s4:bgfs-a"# Virtual IP-2 for Node A (replace with your actual VIP)-inet:"10.16.11.103/24"nic_iflabel:"enp0s5:bgfs-a"dg:uuids:-id:0# Replace with actual UUID(dg0) from `create_bgfs_raid.py query-dg`uuid: <a-dg-storage-uuid>-id:9# Replace with actual UUID(dg9) from `create_bgfs_raid.py query-dg`md_uuid: <a-md-dg-meta-uuid>-name: b-group# prefer_node: node for Node Bprefer_node:"bgfs-oss2"vip:# Virtual IP-1 for Node B (replace with your actual VIP)-inet:"10.16.10.104/24"# Network interface (replace with your actual interface)nic_iflabel:"enp0s4:bgfs-b"# Virtual IP-2 for Node B (replace with your actual VIP)-inet:"10.16.11.104/24"nic_iflabel:"enp0s5:bgfs-b"dg:uuids:-id:0# Replace with actual UUID(dg0) from `create_bgfs_raid.py query-dg`uuid: <b-dg-storage-uuid>-id:9# Replace with actual UUID(dg1) from `create_bgfs_raid.py query-dg`md_uuid: <b-md-dg-meta-uuid>
Each group represents a logical set of resources that move together during failover
prefer_node: The node where this group runs under normal conditions
vip: Virtual IP configuration
inet: The virtual IP address with subnet mask (CIDR notation)
nic_iflabel: The network interface and label
dg: Drive group configuration
uuids: List of drive group UUIDs obtained from create_bgfs_raid.py query-dg
Note
mgt-vip must NOT match the IP address of either Node A or Node B; please specify a unique IP address.
The UUIDs for a-group must be obtained from running the query-dg command on Node A (bgfs-oss1).
The UUIDs for b-group must be obtained from running the query-dg command on Node B (bgfs-oss2).
Critical Configuration Notes:
Drive Group UUIDs: These are unique identifiers for your RAID groups and must be correct. Use the create_bgfs_raid.py query-dg command to get the exact UUIDs for your configuration.
Network Interfaces: Ensure that the network interfaces specified in the nic_iflabel fields actually exist on your systems. Use ip link show to verify.
Virtual IP Addresses: The virtual IPs must be on the same subnet as your physical interfaces but should not be already in use.
Filesystem Types: The default configuration uses ext4 for metadata and xfs for storage. Change these only if you have specific requirements.
Mount Options: The x-systemd.requires=graid.service option ensures that the SupremeRAID™ service is running before mounting. This is crucial for proper operation.
Security: Remember to change default passwords (ssh_password, cluster_password, and BMC credentials) in production environments.
After editing the configuration file, save it and verify that the YAML syntax is correct:
This deployment script is designed for BeeGFS 7.4.6. Support for BeeGFS 8.x will be provided in a future update. The verification commands differ between these versions.
Please use the commands corresponding to your BeeGFS version. Check BeeGFS Version:
# For BeeGFS 8 versionbeegfs version# For BeeGFS 7 versionsbeegfs-ctl --version
Verify that all BeeGFS services are running correctly:
# Check status of management servicebeegfs-ctl --listnodes--nodetype=mgmtd --detail--nicdetail--routes# Check status of metadata servicesbeegfs-ctl --listnodes--nodetype=meta --detail--nicdetail--routes# Check status of storage servicesbeegfs-ctl --listnodes--nodetype=storage --detail--nicdetail--routes# Check status of client servicesbeegfs-ctl --listnodes--nodetype=client --detail--nicdetail--routes# Check status of clientbeegfs-ctl --clientstats# Check df of beegfsbeegfs-df# Check the client connectionbeegfs-net
BeeGFS 8 introduces the unified beegfs command. The old beegfs-ctl and beegfs-check-servers tools are replaced by subcommands within this new tool.
Key Syntax Changes: beegfs-check-servers ➔ beegfs health check beegfs-ctl --listnodes ➔ beegfs node list beegfs-df ➔ beegfs health df beegfs-ctl --getentryinfo ➔ beegfs entry info
# [Recommended] Cluster Health Check# This replaces beegfs-check-servers and performs a comprehensive check # of node reachability and status across the cluster.beegfs health check# List all Management nodes with network detailsbeegfs node list --node-type=mgmtd --with-nics # List all Metadata nodes with network details and reachability statusbeegfs node list --node-type=meta --with-nics --reachability-check# List all Storage nodes with network details and reachability statusbeegfs node list --node-type=storage --with-nics --reachability-check# List all Client nodesbeegfs node list --node-type=client --with-nics# Check Client I/O Statisticsbeegfs stats client# Check BeeGFS capacity usage (Disk Free)# Displays usage for storage targets and poolsbeegfs health df# Check BeeGFS connections beegfs health net # Verify a specific mount path (Optional)# This replaces beegfs-ctl --getentryinfobeegfs entry info /mnt/beegfs
The beegfs_control.py script can automatically configure and mount the BeeGFS client if the client section in beegfs_manager_config.yaml is properly filled out.
Alternatively, if you prefer to set up the BeeGFS client service manually on your client nodes, follow these steps:
Install BeeGFS Client Packages: Refer to the official BeeGFS website for detailed instructions on installing the necessary client packages for your operating system.
Copy Authentication File: The authentication file, conn_auth or auth, located on the BeeGFS server at /etc/beegfs/conn_auth, must be copied to /etc/beegfs/conn_auth or /etc/beegfs/auth on each client node to ensure proper authentication.
Before proceeding with client mounting and read/write operations, it is mandatory to ensure that the PCS Cluster and BeeGFS services are successfully deployed and in a healthy state. Please perform the following verification steps in sequence:
Cluster Status Check(Server Side): First, verify the Pacemaker cluster status on a management node (Node A or Node B) to ensure that all resources (VIPs, file systems, BeeGFS services) are Started and error-free.
sudo pcs status
Expected Result: All Resource Groups should show as Started and be distributed across the expected nodes. Example:
pcs statusCluster name: graid-clusterCluster Summary: * Stack: corosync (Pacemaker is running) * Current DC: bgfs-oss1 (version 2.1.6-6fdc9deea29) - partition with quorum * Last updated: Thu Dec 18 09:40:49 2025 on bgfs-oss1 * Last change: Wed Dec 1714:31:39 2025 by root via cibadmin on bgfs-oss1 * 2 nodes configured * 38 resource instances configured (1 DISABLED)Node List: * Online: [ bgfs-oss1 bgfs-oss2 ]Full List of Resources: * graid-kv (ocf:heartbeat:Dummy): Stopped (disabled) * mgt-vip (ocf:heartbeat:IPaddr2): Started bgfs-oss1 * a-vip-stor1 (ocf:heartbeat:IPaddr2): Started bgfs-oss1 * a-vip-stor2 (ocf:heartbeat:IPaddr2): Started bgfs-oss1 * b-vip-stor1 (ocf:heartbeat:IPaddr2): Started bgfs-oss2 * b-vip-stor2 (ocf:heartbeat:IPaddr2): Started bgfs-oss2 * mgt-dg9 (ocf:graid:md_dg_daemon_py): Started bgfs-oss1 * a-dg0 (ocf:graid:dg_daemon_py): Started bgfs-oss1 * b-dg0 (ocf:graid:dg_daemon_py): Started bgfs-oss2 * b-dg9 (ocf:graid:md_dg_daemon_py): Started bgfs-oss2 * mgt-fs (ocf:heartbeat:Filesystem): Started bgfs-oss1 * a-fs-meta1 (ocf:heartbeat:Filesystem): Started bgfs-oss1 * a-fs-meta2 (ocf:heartbeat:Filesystem): Started bgfs-oss1 * a-fs-meta3 (ocf:heartbeat:Filesystem): Started bgfs-oss1 * a-fs-meta4 (ocf:heartbeat:Filesystem): Started bgfs-oss1 * a-fs-storage1 (ocf:heartbeat:Filesystem): Started bgfs-oss1 * a-fs-storage2 (ocf:heartbeat:Filesystem): Started bgfs-oss1 * b-fs-meta1 (ocf:heartbeat:Filesystem): Started bgfs-oss2 * b-fs-meta2 (ocf:heartbeat:Filesystem): Started bgfs-oss2 * b-fs-meta3 (ocf:heartbeat:Filesystem): Started bgfs-oss2 * b-fs-meta4 (ocf:heartbeat:Filesystem): Started bgfs-oss2 * b-fs-storage1 (ocf:heartbeat:Filesystem): Started bgfs-oss2 * b-fs-storage2 (ocf:heartbeat:Filesystem): Started bgfs-oss2 * mgt-bgfs (ocf:beegfs:beegfs-mgmt-daemon): Started bgfs-oss1 * a-bgfs-meta1 (ocf:beegfs:beegfs-meta-daemon): Started bgfs-oss1 * a-bgfs-meta2 (ocf:beegfs:beegfs-meta-daemon): Started bgfs-oss1 * a-bgfs-meta3 (ocf:beegfs:beegfs-meta-daemon): Started bgfs-oss1 * a-bgfs-meta4 (ocf:beegfs:beegfs-meta-daemon): Started bgfs-oss1 * a-bgfs-storage1 (ocf:beegfs:beegfs-storage-daemon): Started bgfs-oss1 * a-bgfs-storage2 (ocf:beegfs:beegfs-storage-daemon): Started bgfs-oss1 * b-bgfs-meta1 (ocf:beegfs:beegfs-meta-daemon): Started bgfs-oss2 * b-bgfs-meta2 (ocf:beegfs:beegfs-meta-daemon): Started bgfs-oss2 * b-bgfs-meta3 (ocf:beegfs:beegfs-meta-daemon): Started bgfs-oss2 * b-bgfs-meta4 (ocf:beegfs:beegfs-meta-daemon): Started bgfs-oss2 * b-bgfs-storage1 (ocf:beegfs:beegfs-storage-daemon): Started bgfs-oss2 * b-bgfs-storage2 (ocf:beegfs:beegfs-storage-daemon): Started bgfs-oss2 * bgfs-oss1-fence (stonith:fence_ipmilan): Started bgfs-oss2 * bgfs-oss2-fence (stonith:fence_ipmilan): Started bgfs-oss1Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabled
Check Mount Status (Client Side) Once the cluster status is confirmed to be normal, verify on the client node that BeeGFS is mounted correctly.
#[Please log in to the Client (bgfs-client) to execute the following command]mount|grep beegfs
Expected Result: The file system type beegfs named beegfs_nodev is detected.
mount|grep beegfsbeegfs_nodev on /mnt/beegfs type beegfs (rw,relatime,cfgFile=/etc/beegfs/beegfs-client.conf,_netdev
Basic Read/Write Test (Client Side) Perform a simple write test on the client to verify data access permissions and network connectivity.
High Availability (HA) Test Verify the failover functionality. It is recommended to perform a manual resource migration to another node while continuous I/O (e.g., writing a large file) is running on the client, to observe if the I/O is interrupted.
pcs node standby bgfs-oss2
Expected Result: All services from bgfs-oss2 should failover to bgfs-oss1.
pcs statusCluster name: graid-clusterCluster Summary: * Stack: corosync (Pacemaker is running) * Current DC: bgfs-oss1 (version 2.1.6-6fdc9deea29) - partition with quorum * Last updated: Thu Dec 18 09:40:49 2025 on bgfs-oss1 * Last change: Wed Dec 1714:31:39 2025 by root via cibadmin on bgfs-oss1 * 2 nodes configured * 38 resource instances configured (1 DISABLED)Node List: * Node bgfs-oss2: standby * Online: [ bgfs-oss1 ]Full List of Resources: * graid-kv (ocf:heartbeat:Dummy): Stopped (disabled) * mgt-vip (ocf:heartbeat:IPaddr2): Started bgfs-oss1 * a-vip-stor1 (ocf:heartbeat:IPaddr2): Started bgfs-oss1 * a-vip-stor2 (ocf:heartbeat:IPaddr2): Started bgfs-oss1 * b-vip-stor1 (ocf:heartbeat:IPaddr2): Started bgfs-oss2 * b-vip-stor2 (ocf:heartbeat:IPaddr2): Started bgfs-oss2 * mgt-dg9 (ocf:graid:md_dg_daemon_py): Started bgfs-oss1 * a-dg0 (ocf:graid:dg_daemon_py): Started bgfs-oss1 * b-dg0 (ocf:graid:dg_daemon_py): Started bgfs-oss2 * b-dg9 (ocf:graid:md_dg_daemon_py): Started bgfs-oss2 * mgt-fs (ocf:heartbeat:Filesystem): Started bgfs-oss1 * a-fs-meta1 (ocf:heartbeat:Filesystem): Started bgfs-oss1 * a-fs-meta2 (ocf:heartbeat:Filesystem): Started bgfs-oss1 * a-fs-meta3 (ocf:heartbeat:Filesystem): Started bgfs-oss1 * a-fs-meta4 (ocf:heartbeat:Filesystem): Started bgfs-oss1 * a-fs-storage1 (ocf:heartbeat:Filesystem): Started bgfs-oss1 * a-fs-storage2 (ocf:heartbeat:Filesystem): Started bgfs-oss1 * b-fs-meta1 (ocf:heartbeat:Filesystem): Started bgfs-oss2 * b-fs-meta2 (ocf:heartbeat:Filesystem): Started bgfs-oss2 * b-fs-meta3 (ocf:heartbeat:Filesystem): Started bgfs-oss2 * b-fs-meta4 (ocf:heartbeat:Filesystem): Started bgfs-oss2 * b-fs-storage1 (ocf:heartbeat:Filesystem): Started bgfs-oss2 * b-fs-storage2 (ocf:heartbeat:Filesystem): Started bgfs-oss2 * mgt-bgfs (ocf:beegfs:beegfs-mgmt-daemon): Started bgfs-oss1 * a-bgfs-meta1 (ocf:beegfs:beegfs-meta-daemon): Started bgfs-oss1 * a-bgfs-meta2 (ocf:beegfs:beegfs-meta-daemon): Started bgfs-oss1 * a-bgfs-meta3 (ocf:beegfs:beegfs-meta-daemon): Started bgfs-oss1 * a-bgfs-meta4 (ocf:beegfs:beegfs-meta-daemon): Started bgfs-oss1 * a-bgfs-storage1 (ocf:beegfs:beegfs-storage-daemon): Started bgfs-oss1 * a-bgfs-storage2 (ocf:beegfs:beegfs-storage-daemon): Started bgfs-oss1 * b-bgfs-meta1 (ocf:beegfs:beegfs-meta-daemon): Started bgfs-oss2 * b-bgfs-meta2 (ocf:beegfs:beegfs-meta-daemon): Started bgfs-oss2 * b-bgfs-meta3 (ocf:beegfs:beegfs-meta-daemon): Started bgfs-oss2 * b-bgfs-meta4 (ocf:beegfs:beegfs-meta-daemon): Started bgfs-oss2 * b-bgfs-storage1 (ocf:beegfs:beegfs-storage-daemon): Started bgfs-oss2 * b-bgfs-storage2 (ocf:beegfs:beegfs-storage-daemon): Started bgfs-oss2 * bgfs-oss1-fence (stonith:fence_ipmilan): Stopped * bgfs-oss2-fence (stonith:fence_ipmilan): Started bgfs-oss1Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabled
Migrate back to the original node
pcs node unstandby bgfs-oss2
Expected Result: All services for bgfs-oss2 should migrate back from bgfs-oss1 to bgfs-oss2.
To completely remove BeeGFS data and configuration (use with caution):
cd /opt/beegfs_setup_manager/# Purge all BeeGFS services and datasudo python3 beegfs_control.py purge# Purge nodes added with the join commandsudo python3 beegfs_control.py purge_join <mgmtd_ip># Purge only Pacemaker resourcessudo python3 beegfs_control.py purge --pcs